
Unicode ist der universell einsetzbare Code für über 40000
Zeichen der verschiedenesten Schriften der Welt. Insbesondere ist Unicode
der Standardzeichensatz für HTML (ab. 4.0), Java und XML.
Der Zeichensatz baut auf einer 16-Bit/Zeichen Darstellung auf. Diese Darstellung kann bei Bedarf auf 32 Bit erweitert werden. Im europäischen Kulturkreis genügen aber immer die 16-Bit. Will man den Code eines solchen Zeichens angeben, schreibt man U+xxxx, wobei die Darstellung hexadezimal ist.
Die Codierung baut auf bekannten Zeichensätzen auf. Die ersten 128-Zeichen entsprechen exakt dem ASCII-Code, die ersten 256 Zeichen dem ISO-8859-1 Code, der auch unter Latin 1 oder Western bekannt ist.
Schreibt man eine Reihe von 16-Bit Werten, die ja für die einzelnen Zeichen stehen, in eine Datei, dann wird die Reihenfolge wichtig. Liest man die Datei Byte für Byte aus, muss man die Frage beantworten, ob zuerst der höhere oder zuerst der niedere Anteil des 16-Bit-Zeichens gelesen wird. Um das zu erkennen, wird eine Kennung an den Anfang gestellt - das BOM-Zeichen (byte order mark, Bytereihenfolge-Marke). Der Wert 0xfeff for die BOM ist so gewählt, dass er nicht zu Verwechslungen führen kann.
Nun können viele DV-Systeme besser mit Bytes als mit 16-Bit-Zeichen umgehen. Daher existiert neben der 16-Bit-Darstellung auch eine 8-Bit-Darstellung des Unicode-Zeichensatzes. Diese Darstellung nennt man UTF-8 (unicode transformation form 8 / Unicode Darstellungsform 8 Bit). Mit UTF-8 wird aus dem 16-Bit-Zeichen eine Zeichenkette, die zwischen ein und drei Byte lang ist. Dabei wird immer die kürzestmögliche Darstellung gewählt. Das führt dazu, dass die ASCII-Zeichen erhalten bleiben.
Wenn wir von unserem normalen Latin 1 Zeichensatz ausgehen, dann werden alle Buchstaben und Steuerzeichen, deren Wert größer als 127 ist, (deren oberstes Bit damit eine "0" ist) in ein genauso aufgebautes UTF-8 umgesetzt. Ein ISO-8859-1-Zeichen "a" (0x41) entspricht somit im Unicode UTF-16 (normale 16-Bit Darstellung) wieder dem "a" mit dem Code 0x0041. Umgesetzt in UTF-8 erhalten wir wieder ein "a" mit dem Code 0x41.
Etwas komplizierter wird das ganze, wenn das höchste Bit gesetzt ist. Wir gehen dabei wieder von einem Zeichen aus, das auch im iso-8859-1 Code enthalten ist. Nehmen wir ein spanisches "n mit Tilde". Es hat den Code U+00f1. Damit ist das höchste Bit im unteren Byte gesetzt. In der UTF-8-Darstellung wird nun geprüft, ob im UTF-16 Code die obersten 5 Bits auf "0" stehen. Dies ist hier natürlich der Fall. In UTF-8 teilt man nun die restlichen 11 Bits (die obersten 5 sind ja "0") in zwei Teile: sechs untere Bits und 5 obere Bits. Das erste Byte besteht und aus einem Vorspann "110" und den fünf oberen Bits, das zweite Byte erhält das Muster "10" und die 6 unteren Bits. Die Ersatzdarstellung für ein spanischen "n mit Tilde" wird also zu 0xc3 und 0xb1.(Die exakte Darstellung der Bit-Gruppen finden Sie am Schluß der Seite im Bild dargestellt.)
Machen wir noch ein Beispiel. Übersetzen wir das BOM (0xfeff) in die UTF-8 Darstellung. In einem Byte ist das nicht zu schaffen, da der Wert größer als 127 ist. Auch die Darstellung mit zwei Zeichen klappt nicht, da die obersten 5 Bits nicht "0" sind. Nun brauchen wir eine 3 Byte Darstellung.
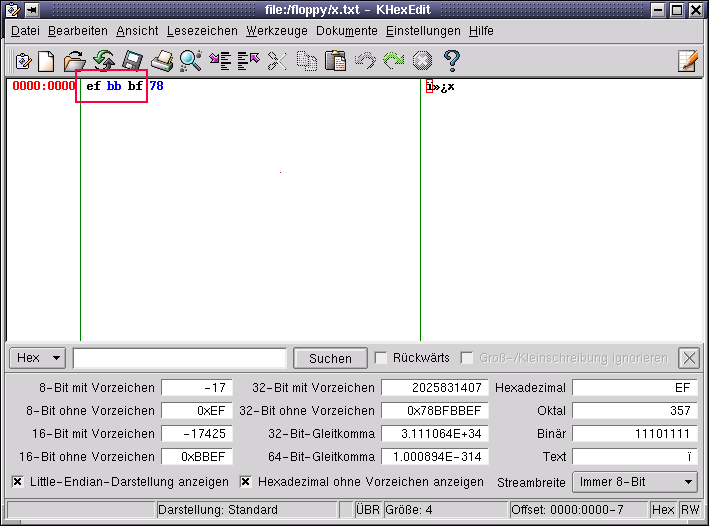
Die 16-Bits werden nun in drei Gruppen mit 4/6/6-Bits gegliedert. Und die Kennungen der einzelnen Bytes sind "1110" für das erste und "10" für die folgenden. Fügt man die einzelnen Bits wieder zusammen und stellt die Bytes dann dar erhalten wir die Bytefolge "0xef, 0xbb und 0xbf". In Dateien, die den Text im UTF-8-Format enthalten, werden diese drei Bytes vorangestellt. Damit wird der ursprüngliche Zweck des BOM's, nämlich die Angabe der Reihenfolge innerhalb eines 16-Bit-Zeichens, natürlich nicht genutzt, da wir ja bei UTF-8 eine Einzelbyte Darstellung besitzen. Aber diese Bytefolge wird zur Identifikation als UTF-8-Datei verwendet.
Diese Kennzeichnung ist aber nicht Pflicht.
Beispiele:
Netscape kann in seinem Composer Dateien im UTF-8-Format erzeugen und
speichern. Hier wird ohne BOM gespeichert, da Browser erst den META-Tag
lesen müssen, um auf UTF-8 umzuschalten.

Im Hexeditor kann man in der Zeile 0080 und 0090 sehen, dass der Zeichensatz UTF-8 in der META-Anweisung gefordert wird. Die Zeichen innerhalb der HTML-Anweisungen sind lesbar, da sie als ASCII-gelesen werden können. Der in UTF-8 codierte Text ist sehr kurz und besteht aus drei "ü" in der Zeile 0110.
Der Texteditor "notepad.exe" unter Windows2000 ist in der Lage, Dateien im UTF-8 Format abzuspeichern. Er kennzeichnet den Beginn der Datei mit einem BOM. Der eigentliche Inhalt ist wieder sehr kuz und besteht nur aus einem einzelnen "x".
Die originale Umsetzungstabelle finden Sie u.a. unter www.unicode.org / Version 3.0 des Unicode Standards / Kapitel 3 / Punkt D36.
Sie sieht so aus: (geringfügige Änderungen in der Version 3.1 betreffen nur 32-Bit-Erweiterungen).
